The Collaboration for AIDS Vaccine Discovery (CAVD) consists of a group of labs across the world, all pooling their data with one goal in mind: to create an AIDS vaccine as fast as possible. But the theory of sharing vast amounts of data is easier than the practice.
“The data sharing policy has been in place for a very long time . . . but it’s hard to actually do that in a way that’s not randomly sharing Excel files,” says Nicole Frahm, CAVD member and associate professor at the University of Washington’s department of global health. “Even though we all work together, sometimes were a little bit siloed.”
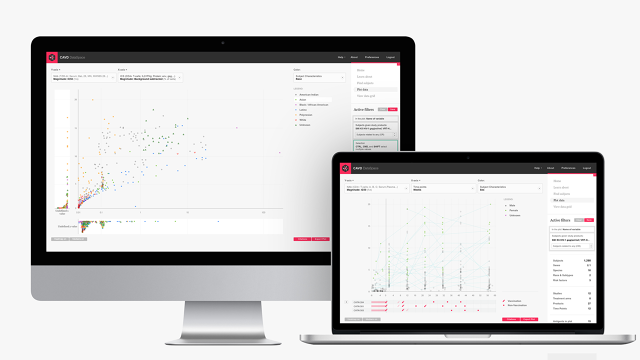
In response to the problem, the statistical analysis firm SCHARP—which crunches data for the group—developed a new platform called DataSpace, working with the design firm Artefact and with funding from the Bill and Melinda Gates Foundation. DataSpace is sort of like using one of those really nicely polished interactive data visualizations, but instead of just mining one big source of data, researchers can actually compare the results of many different scientific studies at once, rearranging patients from different trials into one simulated study. In turn, they can instantly chart how patients across studies responded to the same drug—with all the data rendered on a perfectly articulated graph with the same timelines.
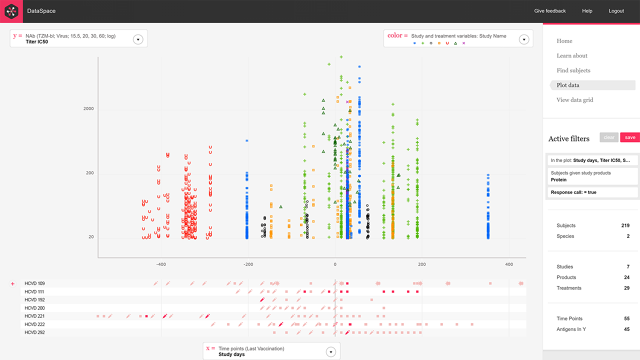
“We’ve already harmonized the data . . . we’ve lined everything up, put it in the space, made it so you could ask questions you didn’t set out to ask,” says Dave McColgin, UX design director at Artefact. “You can sort of stumble into additional questions, if that makes sense.”
Frahm, who worked with Artefact in the early rollout of DataSpace, refers to the platform as a hypothesis engine. While it’s hard to see in these screens, everything is linked, as if you’re surfing Wikipedia and can continually do a deeper and deeper dive on a subject. The secret sauce is that aforementioned data harmonization. Artefact learned which sorts of data points were most helpful in HIV research from scientists, and, working with LabKey and SCHARP, hand-coded that data into the back-end of DataSpace so they could be easily correlated and compared. Basically, the graphs are nice—but the real magic of the platform is thanks to the invisible labor ensuring all study results were presented in the same apples-to-apples figures.
DataSpace’s primary goal is to surface the data hiding in published papers, making it more accessible and comparable at the same time. But what about all the papers that don’t make it to journals for whatever reason? DataSpace’s even greater contribution could be as a venue to share raw data that, just because it lacks an earth-shattering discovery or conclusion, wouldn’t be published and made public.
“Our currency in science is publications, so you have to get publications out,” Frahm says. The problem is that to publish something in a journal, you need results—in this case, proof that a potential HIV vaccine made some measurable impact on the virus’s spread. Because they aren’t published, all of those failed studies—the funded research in which scientists spent valuable time and money learning some vaccines didn’t work—may be duplicated by another lab making the same mistakes.
“People won’t publish things with negative results,” Frahm says, referring to the long-standing phenomenon known as publication bias. “People won’t publish that information, and that’s data that could be uploaded into the system.” DataSpace, specifically because it’s not a platform for scientific papers but for data itself, could be a collection point for all of the studies generating null results.
For now, DataSpace is built only with a select set of CAVD data. In the future, however, Artefact imagines it could serve researchers across medical disciplines. “We’ve learned from people working on tuberculosis or malaria, you want to be able to compare those studies or tests,” McColgin says. “We think the basic patterns of how data is organized . . . are all in common with other diseases.”
